1.3 JIT - A hand-made function
- Allocating memory
- Filling it with instructions
- Endianness
- Operator enums to x86
- Calling conventions
- Ops breakdown: Print, Exit, Draw
- Running the JIT
- Drop
This will be a Just-In-Time compiled function in x86_64 CPU byte-ops, using
the System V AMD64 ABI.
All going well it should work on Linux, Mac and Windows.
Using the JIT goes as follows:
- allocate some read-write memory, represented by
JitMemory - fill the memory with instrucion bytes while iterating over a
Vec<Operator> - mark the allocated memory as executable,
JitMemory::to_jit_fn()should return aJitFn - call it as a function with
JitFn::run(), which transmutes the pointer to the executable memory into a function pointer and calls that pointer
This memory has to be requested in multiples of the page size
supported by the CPU, for x86_64 the smallest valid size is 4k.
The OS will not allow a memory region to be both writable and executable at the same time, so these stages have to be clearly separated.
JitMemory keeps track of the address, the size we requested and the index
offset where we are going to write the next byte.
JitFn maps to an address already marked as executable.
// jit/mod.rs
// Allocate memory sizes as multiples of 4k page.
const PAGE_SIZE: usize = 4096;
/// An executable memory buffer filled with `x86` instructions.
pub struct JitFn {
addr: *mut u8,
size: usize,
}
/// A read-write memory buffer allocated to be filled with bytes of `x86`
/// instructions. This is a private struct, use `JitFn::new()`. This way the
/// allocated memory address is only freed when the JitFn goes out of scope.
struct JitMemory {
addr: *mut u8,
size: usize,
/// current position for writing the next byte
offset: usize,
}
Allocating memory
The allocated memory block has to be aligned on a boundary of 16 bytes, otherwise we won’t be able to use it as an executable function on both Windows, Mac and Linux.
On Linux and Mac, libc::malloc() simply allocates a block at the next
convenient address, and doesn’t guarantee any kind of alignment.
The libc manual points out 3.2.3.6 Allocating Aligned Memory
Blocks, which describes posix_memalign(). The function signature is:
int posix_memalign (void **memptr, size_t alignment, size_t size)
We can use this to request an aligned memory block of a certain size, then use
mprotect() to mark it as read-write.
Because this memory can contain anything when we get it, it’s a good idea to use
memset() to fill it with ret calls (0xC3), so if our function moves to an
unexpected instruction, at least it will just return.
posix_memalign() sets a C **void type pointer in the first argument. We have
to transmute this to a *mut u8 Rust type, then we are good to go.
// jit/mod.rs
impl JitMemory {
/// Allocates read-write memory aligned on a 16 byte boundary.
#[cfg(any(target_os = "linux", target_os = "macos"))]
pub fn new(num_pages: usize) -> JitMemory {
let size: usize = num_pages * PAGE_SIZE;
let addr: *mut u8;
unsafe {
// Take a pointer
let mut raw_addr: *mut libc::c_void = mem::uninitialized();
// Allocate aligned to page size
libc::posix_memalign(&mut raw_addr,
PAGE_SIZE,
size);
// Mark the memory as read-write
libc::mprotect(raw_addr,
size,
libc::PROT_READ | libc::PROT_WRITE);
// Fill with 'RET' calls (0xc3)
libc::memset(raw_addr, 0xc3, size);
// Transmute the c_void pointer to a Rust u8 pointer
addr = mem::transmute(raw_addr);
}
JitMemory {
addr: addr,
size: size,
offset: 0,
}
}
}
On Windows, we can use VirtualAlloc, the function signature is:
LPVOID WINAPI VirtualAlloc(
_In_opt_ LPVOID lpAddress,
_In_ SIZE_T dwSize,
_In_ DWORD flAllocationType,
_In_ DWORD flProtect
);
And so the equivalent JitMemory::new() for Windows:
// jit/mod.rs
impl JitMemory {
#[cfg(target_os = "windows")]
pub fn new(num_pages: usize) -> JitMemory {
let size: usize = num_pages * PAGE_SIZE;
let addr: *mut u8;
unsafe {
// Take a pointer
let raw_addr: *mut winapi::c_void;
// Allocate aligned to page size
raw_addr = kernel32::VirtualAlloc(
ptr::null_mut(),
size as u64,
winapi::MEM_RESERVE | winapi::MEM_COMMIT,
winapi::winnt::PAGE_READWRITE);
if raw_addr == 0 as *mut winapi::c_void {
panic!("Couldn't allocate memory.");
}
// NOTE no FillMemory() or SecureZeroMemory() in the kernel32 crate
// Transmute the c_void pointer to a Rust u8 pointer
addr = mem::transmute(raw_addr);
}
JitMemory {
addr: addr,
size: size,
offset: 0,
}
}
}
Filling it with instructions
The JitAssembler trait describes what JitMemory will have to implement so
that we can assemble our function.
push_u8() puts in single-byte values. We can use this to construct 4-byte
u32 and 8-byte u64 values in the memory, fill_jit() makes use of these.
Eventually to_jit_fn() marks the memory block as executable and returns a
JitFn where we can use JitFn::run() to call the function.
// jit/mod.rs
pub trait JitAssembler {
/// Marks the memory block as executable and returns a `JitFn` containing
/// that address.
fn to_jit_fn(&mut self) -> JitFn;
/// Fills the memory block with `x86` instructions while iterating over a
/// list of `Operator` enums.
fn fill_jit(&mut self, context: &mut Context, operators: &Vec<Op>);
/// Writes one byte to the memory at the current index offset and increments
/// the offset.
fn push_u8(&mut self, value: u8);
/// Writes a 4-byte value. `x86` specifies Little-Endian encoding,
/// least-significant byte first.
fn push_u32(&mut self, value: u32);
/// Writes an 8-byte value.
fn push_u64(&mut self, value: u64);
}
Implementing push_u8() assigns the value to the byte at addr + offset and
increments the offset.
// jit/mod.rs
fn push_u8(&mut self, value: u8) {
unsafe { *self.addr.offset(self.offset as _) = value };
self.offset += 1;
}
Endianness
Implementing push_u32() and push_u64() has to construct these multi-byte
values from single bytes, and the CPU architecture will specify if we must use
either Little-Endian or Big-Endian encoding, or can do both.
At least this doesn’t vary between OSes, the CPU specifies it, and
the Endianness table tells us that all the x86 CPUs stick to
Little-Endian (LE).
The naming is counter-intuitive, the “end” refers to the front- or starting end (first byte by pointer address), not to the “final portion” end (last byte by pointer address).
There are advantages in this for the machine. The pointer address points to the first byte, and casting between interger types doesn’t need to relocate the bytes, just ignore or append to the end.
For small intergers it will even preserve the value:
| type | bytes (LE) | value |
|---|---|---|
u32 |
7A 00 00 00 |
122 |
u16 |
7A 00 |
122 |
u32 |
0D 0C 0B 0A |
168496141 |
u16 |
0D 0C |
3085 |
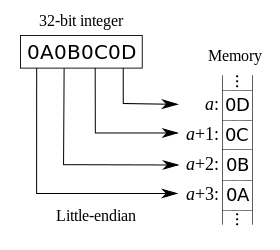
(Diagram from the Endianness Wikipedia page.)
Implementing it means bit-shifting the value, zeroing the higher bits by taking
a bitwise & with 0xFF and what’s left is an u8 byte:
// jit/mod.rs
fn push_u32(&mut self, value: u32) {
self.push_u8(((value >> 0) & 0xFF) as u8);
self.push_u8(((value >> 8) & 0xFF) as u8);
self.push_u8(((value >> 16) & 0xFF) as u8);
self.push_u8(((value >> 24) & 0xFF) as u8);
}
Operator enums to x86
We expressed the operations we want to happen with a list of enums, it’s time to
fill the JIT (that is, write the instructions to memory) with a function that
iterates over those enums, while also passing an &mut Context pointer so we
can manipulate the application’s state.
fn fill_jit(&mut self, context: &mut Context, operators: &Vec<Operator>);
By convention we have to start our program with the function prologue and end with the epilogue. If you were writing assembly on Linux or Mac:
; prologue
push rbp
mov rbp, rsp
; ... action and excitement
; epilogue
mov rsp, rbp
pop rbp
ret
And so we have to put the equivalent byte opcodes in the memory. To preserve our sanity we will compose small functions which put in a few bytes at a time.
This way, when we have our JitMemory, we can call these one after the other as
if writing assembly.
For example the push_rbp() and mov_rbp_rsp() would be:
// jit/mod.rs
impl JitMemory {
pub fn push_rbp(&mut self) {
self.push_u8(0x55);
}
pub fn mov_rbp_rsp(&mut self) {
self.push_u8(0x48);
self.push_u8(0x89);
self.push_u8(0xe5);
}
}
And then we can use this in fill_jit() to start and end our hand-made
function, and in between we can implement action and excitement!
// jit/mod.rs
impl JitAssembler for JitMemory {
fn fill_jit(&mut self, context: &mut Context, operators: &Vec<Op>) {
// prologue
self.push_rbp();
self.mov_rbp_rsp();
for op in operators.iter() {
match *op {
Op::NOOP => (),
Op::Draw(sprite_idx, offset, speed) => {
/* push x86 byte instructions to memory as if writing
assembly, but we are assembling the machine code directly */
},
Op::Print => { /* ... */ },
Op::Clear(charcode) => { /* ... */ },
Op::Exit(limit) => { /* ... */ },
}
}
// epilogue
self.mov_rsp_rbp();
self.pop_rbp();
self.ret();
}
}
Calling conventions
Linux and Mac
The Linux x86_64 ABI is sysv64, the first few arguments are passed in
registers, any remaining ones are passed on the stack.
The first six integer arguments are passed in:
rdi, rsi, rdx, rcx, r8, r9
Floating-point arguments are passed in xmm0 - xmm7.
The function prologue and epilogue will be:
; prologue
push rbp
mov rbp, rsp
; function body
; - put function arguments in registers
; - put the Rust function pointer in rax
call rax
; epilogue
mov rsp, rbp
pop rbp
ret
The rsp register must point to an address on a 16-byte boundary before the
call jumps. Remember that call will push rdi, moving rsp with -8 bytes
immediately before the jump.
In the prologue we made one push (rsp moved -8 bytes), and call will add
another push (-8 again), which is -16, so we don’t have to sub the value in
rsp to adjust.
At that point we can call the address of the Rust function which corresponds to the operator enum.
If we were counting wrong, we would find out here, because our JIT function would segfault.
After the call, it is good to note that if we didn’t have enough registers for
the function arguments and we pushed the remaining ones to the stack, then here
we would have to clean up (the stack) by adding to the address value of rsp.
But there is no cleaning to do at this time and we can just finish after the call.
Windows
We don’t have to write the JIT assembler two times. Rust will compile the extern
sysv64 functions on Windows as well.
Ops breakdown: Draw
Op::Draw(u8, u8, f32)
Defining the function in the trait:
// jit/ops.rs
pub trait Ops {
extern "sysv64" fn op_draw(&mut self, sprite_idx: u8, offset: u8, speed: f32);
}
impl Ops for Context {
extern "sysv64" fn op_draw(&mut self, sprite_idx: u8, offset: u8, speed: f32) {
self.impl_draw(sprite_idx, offset, speed);
}
}
While the actual implementation is on the Context struct:
impl Context {
/// Write a text sprite into the buffer, starting at `offset` and moving
/// with `speed`.
pub fn impl_draw(&mut self, sprite_idx: u8, offset: u8, speed: f32) {
if (sprite_idx as usize) < self.sprites.len() {
let total_offset: usize = ((offset as f32 + self.time * speed) % (self.buffer.len() as f32)) as usize;
let ref sprite = self.sprites[sprite_idx as usize];
let mut v: Vec<char> = vec![];
for ch in sprite.chars() { v.push(ch); }
for i in 0 .. v.len() {
let n = (total_offset + i) % self.buffer.len();
self.buffer[n] = v[i];
}
}
}
}
We will take the memory address of this and This is what we call in the JIT.
That is, we call from the JIT to a Rust function, where &mut self is a &mut
Context, so the first argument is that pointer address (integer value).
In addition we are passing integer and float arguments as well. And so in
fill_jit():
// jit/mod.rs
// Linux and Mac
Op::Draw(sprite_idx, offset, speed) => {
// rdi: pointer to Context (pointer is an integer value)
self.movabs_rdi_u64( unsafe { mem::transmute(context as *mut _) });
// rsi: sprite_idx arg. (interger)
self.movabs_rsi_u64(sprite_idx as u64);
// rdx: offset arg. (interger)
self.movabs_rdx_u64(offset as u64);
// xmm0: speed arg. (floating point)
self.movss_xmm_n_f32(0, speed);
self.movabs_rax_u64( unsafe { mem::transmute(
Ops::draw as extern "sysv64" fn(&mut Context, u8, u8, f32)
)});
self.call_rax();
},
Running the JIT
The function we crated byte-by-byte is ready to be executed.
In the main drawing loop, we call the JIT function at every frame, passing it a
&mut Context pointer.
// jit/mod.rs
impl JitFn {
pub fn run(&self, context: &mut Context) {
if self.size == 0 {
return;
}
unsafe {
// type signature of the jit function
let fn_ptr: extern fn(&mut Context);
// transmute the pointer of the executable memory to a pointer of the jit function
fn_ptr = mem::transmute(self.addr);
// use the function pointer
fn_ptr(context)
}
}
}
Drop
Since we allocated this piece of memory manually, we are also responsible for
freeing it. libc::munmap and kernel32::VirtualFree() will do the job. The
signatures:
// Linux and Mac
int munmap (void *addr, size_t length)
// Windows
BOOL WINAPI VirtualFree(
_In_ LPVOID lpAddress,
_In_ SIZE_T dwSize,
_In_ DWORD dwFreeType
);
The user should use JitFn::new(), giving them an already executable memory address.
JitFn::new(num_pages: usize, context: &mut Context, operators: &Vec<Op>) -> JitFn
JitMemory (a writable memory) is a private struct used only by the lib, so the
user can’t end up with both a JitFn and JitMemory storing the same memory
address.
The memory address we allocated is then stored by JitFn. The variable assigned
to JitFn will be freed when it goes out of scope, but nobody knows about this
other piece of memory we allocated, so we have to implement freeing that as
well.
We can implement the Drop trait to do additional clean-up at the time when
JitFn goes out of scope.
// jit/mod.rs
impl Drop for JitFn {
#[cfg(any(target_os = "linux", target_os = "macos"))]
fn drop(&mut self) {
unsafe { libc::munmap(self.addr as *mut _, self.size); }
}
#[cfg(target_os = "windows")]
fn drop(&mut self) {
unsafe { kernel32::VirtualFree(self.addr as *mut _, 0, winapi::MEM_RELEASE); }
}
}